C++程序性能优化(一)- 软件构建阶段
本文最后更新于:8 个月前
最近看到一个cppcon的演讲视频,详细介绍了C++程序性能优化的各种方法,演讲者甚至还是个高中生,大受震撼,决定总结一下视频,结合实际工作中遇到的情况,记录到博客中。(主要基于嵌入式Linux 平台、C++17标准 以及 GCC+CMAKE构建)
参考资料:The Most Important Optimizations to Apply in Your C++ Programs - cppcon2022
性能优化的总体原则
- 避免不必要工作
- 避免不必要拷贝
- 避免不必要内存申请
- 利用所有计算资源
- 使用所有核心
- 使用SIMD
- 避免阻塞和停顿
- 使用无锁数据结构
- 异步调用
- 使用作业系统(这里指的应该是unity的job system,基于线程池)
- 高效使用硬件
- 代码缓存友好(cache friendliness)
- 代码可良好预测(well predictable)
- 提升系统层面的效率
基于以上原则,可以大致将性能优化手段分为三个层面:
- 软件构建阶段的修改
- C++的有效使用
- 针对硬件的相关优化

所有优化手段都应被视为可能有效(也可能负优化),需在开发分支/环境中进行修改,在性能基准测试后再合并。
同时在进行性能分析profiling之前,不应过早地进行性能优化。
软件构建阶段的修改
1.开启编译器优化选项
设置-O2或-O3编译优化以提升程序运行速度,若还想进一步缩减生成的二进制文件体积,可以开启-Os
可以查看当前编译工具链对应优化等级具体启用了哪些优化项
g++ -O2 -Q --help=optimizers,但是这里看不到RVO和NRVO,手动添加-fno-elide-constructors可以禁用RVO优化之前遇到开启编译优化后,程序运行到某个函数就崩溃的问题,而且仅在这个函数内操作了堆内存时才崩溃。后来发现是这个非void函数没写return,相当于汇编层面没有ret语句,程序执行完之后无法跳转回调用位置,甚至会拼接上调用者的指令流,导致严重的段错误
2.指定CPU架构
设置-mcpu=<cpu>以指定目标 CPU,允许编译器启用该 CPU 支持的 所有指令集扩展(例如ARM 的NEON),同时会对代码生成进行调优(调度指令、内存布局、分支预测等,等价于只设置-mtune=<cpu>)
- 查看
cat /proc/cpuinfo结果中CPU part的值(例如0xd05),查找官方手册中对应的cpu核心名称。也可以参考这个开源项目收集的数据 ARM CPU核心信息表
3.启用fast math
设置-ffast-math可以加快浮点运算,可能破坏程序的数学精度或正确性,不适用于对 NaN、Inf、有符号零敏感的代码
4.禁用异常和RTTI
设置-fno-exceptions以禁用异常,当代码中存在异常处理时会出错。设置-fno-rtti以禁用RTTI。这两个操作的收益有限,需谨慎考虑
5. 启用链接时优化
编译器无法跨编译单元优化,一般而言,一个cpp源文件就是一个编译单元,编译器无法将内联另一个cpp文件中的函数。配置-flto开启链接时优化,但建议所有参与链接的动态库都开启 -flto,否则可能报错。
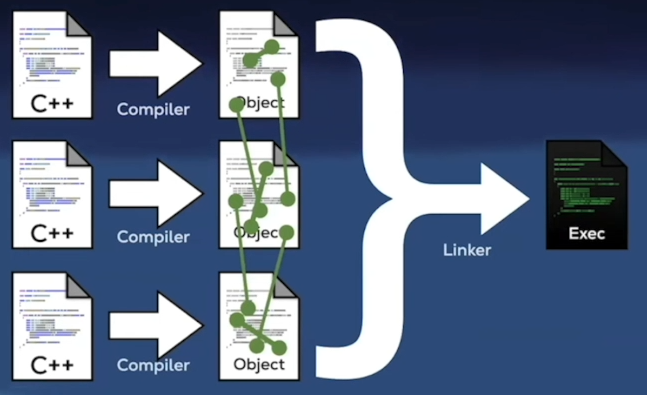
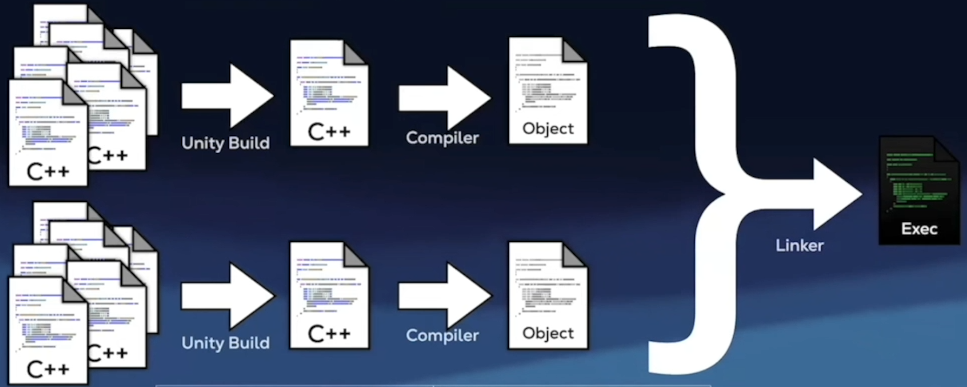
6. 启用联合构建
把多个源文件合并编译,减少重复的预处理和编译工作,从而缩短编译时间,并且编译器有机会对“跨源文件”的函数做更充分的内联和优化。
CMake 从 3.16 起原生支持 Unity Build,添加
set_target_properties(my_target PROPERTIES UNITY_BUILD ON)可开启内联编译,也可以设置以下参数来控制具体行为:1
2
3
4
5set_target_properties(my_target PROPERTIES
UNITY_BUILD ON
UNITY_BUILD_BATCH_SIZE 8 # 每个unity源文件包含几个.cc
UNITY_BUILD_MODE GROUP # 还可以是 "BATCH"
)Unity Build后,如果多个cpp中存在同名static函数,会报重复定义冲突。如果仅个别文件冲突,可以将它们排除出 Unity Build,通过配置
set_source_files_properties(file1.cpp PROPERTIES SKIP_UNITY_BUILD_INCLUSION ON)实现Unity Build会改变源码行数,增加调试难度,最好在最终release版本时使用
7.尽量使用静态链接
仅针对性能而言,静态库在编译时能够被编译器更好地优化
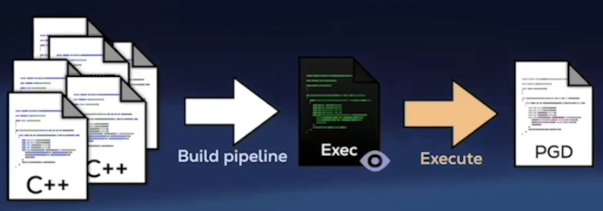
8.基于的性能分析profile的优化
编译器优化时基于启发式的猜测,生成对硬件分支预测器友好的代码。如果使用真实运行时采集的数据代替启发式猜测,可能会有所帮助。具体步骤是先开启-fprofile-generate配置,在编译时插入各种性能计数器,构建程序。此时运行程序会生成一个带有性能分析结果的文件(也可以运行多次,将结果组合在一起)。
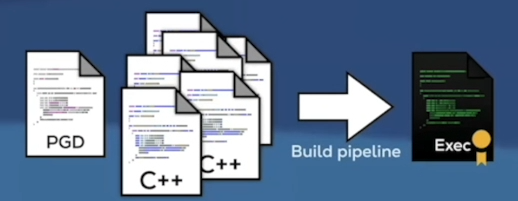
再开启-fprofile-use配置项,将分析结果作为输入重新编译。
9.尝试多种编译器
可以尝试多种编译器编译,再使用兼容的链接器链接。
由于嵌入式平台程序通常需要使用交叉编译链,基本不用考虑
10.尝试不同的标准库
例如大内存时使用ps_malloc代替标准库,或使用mimalloc等(只听过没用过…)
11.预加载替代库
可以使用LD_PRELOAD预加载库而不必重新链接,一般还是用于更快速的malloc库,例如env LD_PRELOAD=/usr/lib/libSUPER_malloc.so ./my_program
12.保持工具更新
编译工具最新版本可能会有一些改进。例如上边cmake3.16之后才支持unity build。虽然平常使用的是交叉编译工具链,但对编译机的cmake版本一般没有要求。
13.使用二进制后处理工具
使用llvm-bolt优化 Clang/LLVM 编译器生成的二进制文件,通过重排代码布局、删除冗余跳转、改进分支预测、结合实际执行的 profile 数据等来提升应用程序的运行效率,特别是启动速度和 CPU Cache 命中率。
但gcc编译的程序能否使用有待测试,似乎不兼容异常处理.eh_frame和
__start入口和部分 PLT/GOT 样式
后续内容放在下一篇博客