本文最后更新于:几秒前
源码 CyberRT 为了解决跨模块数据队列的性能瓶颈,实现了一个无锁(Lock-Free)+有界(Bounded) 的环形队列 BoundedQueue,既能保证高并发下的吞吐率,又能控制内存占用。
相比传统的 std::queue + mutex,它的特点是:
无锁 :采用 std::atomic + CAS(Compare-And-Swap)实现多线程安全,不阻塞生产者或消费者。有界 :队列大小固定,避免动态分配内存造成的抖动。缓存友好 :关键原子变量对齐到缓存行(alignas(CACHELINE_SIZE)),减少 false sharing。可配置等待策略 :支持不同的 WaitStrategy(休眠、忙等、自旋等)来适配不同延迟/功耗需求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 #include <unistd.h> #include <algorithm> #include <atomic> #include <cstdint> #include <cstdlib> #include <memory> #include <utility> #define cyber_likely(x) (__builtin_expect((x), 1)) #define cyber_unlikely(x) (__builtin_expect((x), 0)) template <typename T>class BoundedQueue {public :using value_type = T;using size_type = uint64_t ;public :BoundedQueue () {}operator =(const BoundedQueue& other) = delete ;BoundedQueue (const BoundedQueue& other) = delete ;BoundedQueue ();bool Init (uint64_t size) bool Init (uint64_t size, WaitStrategy* strategy) bool Enqueue (const T& element) bool Enqueue (T&& element) bool WaitEnqueue (const T& element) bool WaitEnqueue (T&& element) bool Dequeue (T* element) bool WaitDequeue (T* element) uint64_t Size () bool Empty () void SetWaitStrategy (WaitStrategy* WaitStrategy) void BreakAllWait () uint64_t Head () return head_.load (); }uint64_t Tail () return tail_.load (); }uint64_t Commit () return commit_.load (); }private :uint64_t GetIndex (uint64_t num) alignas (CACHELINE_SIZE) std::atomic<uint64_t > head_ = {0 };alignas (CACHELINE_SIZE) std::atomic<uint64_t > tail_ = {1 };alignas (CACHELINE_SIZE) std::atomic<uint64_t > commit_ = {1 };uint64_t pool_size_ = 0 ;nullptr ;nullptr ;volatile bool break_all_wait_ = false ;template <typename T>BoundedQueue () {if (wait_strategy_) {BreakAllWait ();if (pool_) {for (uint64_t i = 0 ; i < pool_size_; ++i) {T ();free (pool_);template <typename T>inline bool BoundedQueue<T>::Init (uint64_t size) {return Init (size, new SleepWaitStrategy ());template <typename T>bool BoundedQueue<T>::Init (uint64_t size, WaitStrategy* strategy) {2 ;reinterpret_cast <T*>(std::calloc (pool_size_, sizeof (T)));if (pool_ == nullptr ) {return false ;for (uint64_t i = 0 ; i < pool_size_; ++i) {new (&(pool_[i])) T ();reset (strategy);return true ;template <typename T>bool BoundedQueue<T>::Enqueue (const T& element) {uint64_t new_tail = 0 ;uint64_t old_commit = 0 ;uint64_t old_tail = tail_.load (std::memory_order_acquire);do {1 ;if (GetIndex (new_tail) == GetIndex (head_.load (std::memory_order_acquire))) {return false ;while (!tail_.compare_exchange_weak (old_tail, new_tail,GetIndex (old_tail)] = element;do {while (cyber_unlikely (!commit_.compare_exchange_weak (NotifyOne ();return true ;template <typename T>bool BoundedQueue<T>::Enqueue (T&& element) {uint64_t new_tail = 0 ;uint64_t old_commit = 0 ;uint64_t old_tail = tail_.load (std::memory_order_acquire);do {1 ;if (GetIndex (new_tail) == GetIndex (head_.load (std::memory_order_acquire))) {return false ;while (!tail_.compare_exchange_weak (old_tail, new_tail,GetIndex (old_tail)] = std::move (element);do {while (cyber_unlikely (!commit_.compare_exchange_weak (NotifyOne ();return true ;template <typename T>bool BoundedQueue<T>::Dequeue (T* element) {uint64_t new_head = 0 ;uint64_t old_head = head_.load (std::memory_order_acquire);do {1 ;if (new_head == commit_.load (std::memory_order_acquire)) {return false ;GetIndex (new_head)];while (!head_.compare_exchange_weak (old_head, new_head,return true ;template <typename T>bool BoundedQueue<T>::WaitEnqueue (const T& element) {while (!break_all_wait_) {if (Enqueue (element)) {return true ;if (wait_strategy_->EmptyWait ()) {continue ;break ;return false ;template <typename T>bool BoundedQueue<T>::WaitEnqueue (T&& element) {while (!break_all_wait_) {if (Enqueue (std::move (element))) {return true ;if (wait_strategy_->EmptyWait ()) {continue ;break ;return false ;template <typename T>bool BoundedQueue<T>::WaitDequeue (T* element) {while (!break_all_wait_) {if (Dequeue (element)) {return true ;if (wait_strategy_->EmptyWait ()) {continue ;break ;return false ;template <typename T>inline uint64_t BoundedQueue<T>::Size () {return tail_ - head_ - 1 ;template <typename T>inline bool BoundedQueue<T>::Empty () {return Size () == 0 ;template <typename T>inline uint64_t BoundedQueue<T>::GetIndex (uint64_t num) {return num - (num / pool_size_) * pool_size_; template <typename T>inline void BoundedQueue<T>::SetWaitStrategy (WaitStrategy* strategy) {reset (strategy);template <typename T>inline void BoundedQueue<T>::BreakAllWait () {true ;BreakAllWait ();
其中涉及到的等待策略类实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class WaitStrategy {public :virtual void NotifyOne () virtual void BreakAllWait () virtual bool EmptyWait () 0 ;virtual ~WaitStrategy () {}class BlockWaitStrategy : public WaitStrategy {public :BlockWaitStrategy () {}void NotifyOne () override notify_one (); }bool EmptyWait () override std::unique_lock<std::mutex> lock (mutex_) ;wait (lock);return true ;void BreakAllWait () override notify_all (); }private :class SleepWaitStrategy : public WaitStrategy {public :SleepWaitStrategy () {}explicit SleepWaitStrategy (uint64_t sleep_time_us) : sleep_time_us_(sleep_time_us) { }bool EmptyWait () override sleep_for (std::chrono::microseconds (sleep_time_us_));return true ;void SetSleepTimeMicroSeconds (uint64_t sleep_time_us) private :uint64_t sleep_time_us_ = 10000 ;
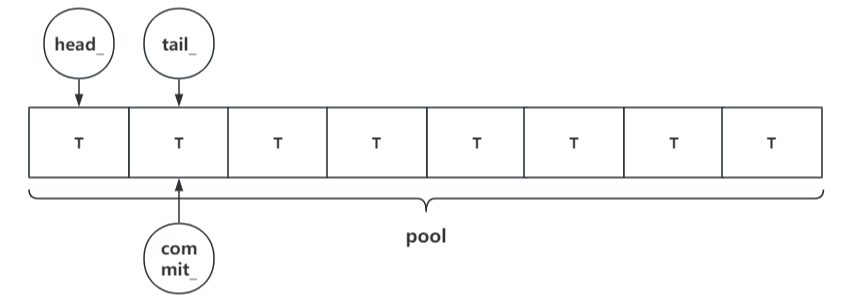
核心数据结构 队列的关键成员变量:
1 2 3 4 5 6 7 8 alignas (CACHELINE_SIZE) std::atomic<uint64_t > head_ = {0 };alignas (CACHELINE_SIZE) std::atomic<uint64_t > tail_ = {1 };alignas (CACHELINE_SIZE) std::atomic<uint64_t > commit_ = {1 };uint64_t pool_size_ = 0 ;nullptr ;nullptr ;volatile bool break_all_wait_ = false ;
**head_**:消费者读到的位置(上一次取出的索引)
**tail_**:生产者预占的位置(正在写入的数据槽位)
**commit_**:已完成写入的数据位置(消费者只能消费到 commit_)
**pool_**:存储数据的环形缓冲区
**wait_strategy_**:等待策略对象(例如 SleepWaitStrategy)
**break_all_wait_**:中断标志,用于安全退出等待状态
这种设计中,tail_ 和 commit_ 的分离是关键:
tail_ 可以先原子递增占坑位(防止多个生产者写同一位置)数据写完后再按序更新 commit_,防止消费者读到未完成的数据,并保证了消费者读到的数据顺序
Enqueue 入队流程
入队分为三个阶段:
申请位置 tail_.compare_exchange_weak 尝试占用下一个可写位置,如果下一位置等于 head_ 说明队列满了:
1 2 3 4 new_tail = old_tail + 1 ;if (GetIndex (new_tail) == GetIndex (head_.load (...))) {return false ;
写入数据 pool_[GetIndex(old_tail)] 写入元素(拷贝或移动)。
提交更新 commit_,通知消费者数据可读:
1 2 3 do {while (!commit_.compare_exchange_weak (old_commit, new_tail, ...));
CAS语义里成功和失败可以指定不同的内存序,但标准规定 failure 内存序不能比 success 内存序更强 ,而且 failure 不能用 release 或 acq_rel,因为失败时不会写入内存。常见组合:
成功 acq_rel / 失败 acquire(要保证失败也看到别人写的数据)
成功 acq_rel / 失败 relaxed(追求性能)
Dequeue 出队流程 出队的核心逻辑:
计算新 head new_head = old_head + 1,如果新 head == commit_,说明没有可读数据。读取数据 pool_[GetIndex(new_head)] 取数据。更新 head head_ 更新到新位置。
这种模式下,消费者永远只读 commit_ 之前的数据,避免读到生产者未写完的内容。
Wait 版本的接口 WaitEnqueue / WaitDequeue 会在队列满/空时使用 wait_strategy_ 进入等待:
1 2 3 if (wait_strategy_->EmptyWait ()) {continue ;
在高负载场景中,使用BusySpinWaitStrategy 可以最大化降低延迟。
在低功耗场景中,使用SleepWaitStrategy 可以减少 CPU 占用。
环形缓冲区索引优化 GetIndex() 采用了乘除法消除 % 模运算:
1 2 3 inline uint64_t GetIndex (uint64_t num) return num - (num / pool_size_) * pool_size_;
这样可以减少除法指令的代价,对高频入队/出队性能提升明显
一些思考 为了支持左值和右值参数,enqueue实现了const T&和T&&两个版本的函数重载,其中的区别只在于pool_[idx]赋值时。可以使用完美转发统一pool_[idx] = std::forward<U>(element);
但函数声明需要修改,因为此时类模板参数和函数模板需要区分成两个,不然无法触发万能引用。还需要保证这两个模板参数能够隐式转换:
1 2 3 template <typename T>template <typename U,typename = std::enable_if_t <std::is_convertible<U, T>::value>>bool BoundedQueue<T>::Enqueue (U&& element)
或者在c++17之后可以稍微简化
1 2 3 4 template <typename T>template <typename U, std::enable_if_t <std::is_convertible_v<U, T>, int > = 0 >bool BoundedQueue<T>::Enqueue (U&& element)
或者使用 if constexpr 做编译期判断
1 2 3 4 5 6 template <typename T>template <typename U>bool BoundedQueue<T>::Enqueue (U&& element) {static_assert (std::is_convertible_v<U, T>, "U must be convertible to T" );